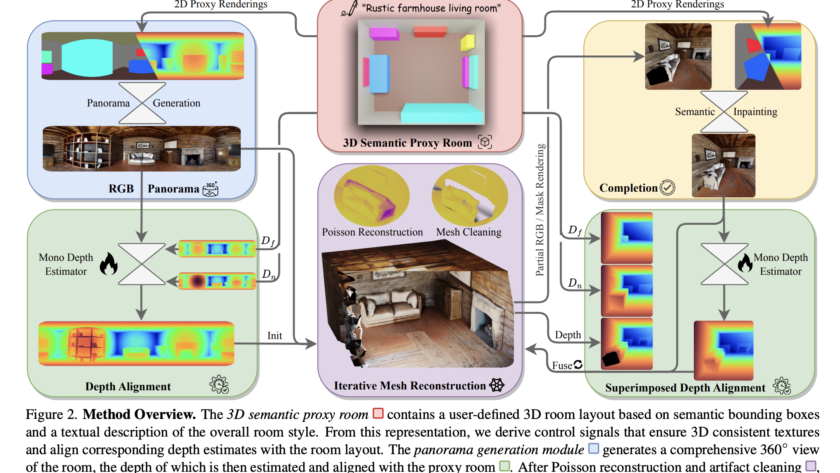
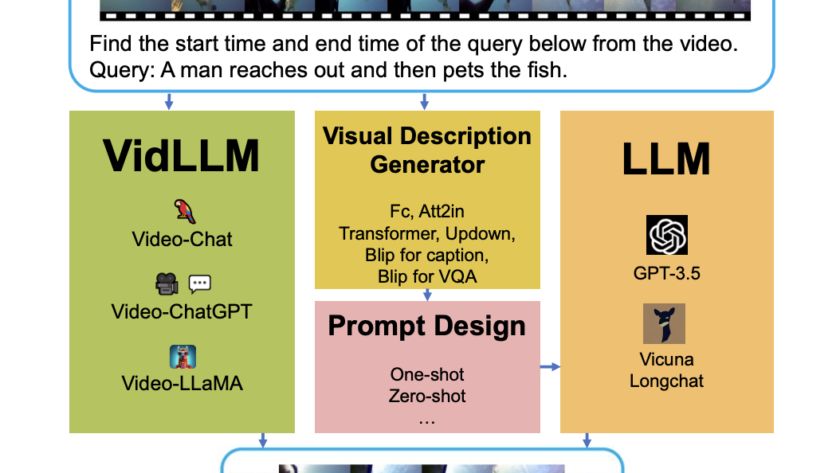
Exploring the Transformer’s Decoder Architecture: Masked Multi-Head Attention, Encoder-Decoder Attention, and Practical Implementation This post was co-authored with Rafael Nardi. In this article, we delve into the decoder component of the transformer architecture, focusing on its differences and similarities with the encoder. The decoder’s unique feature is its loop-like, iterative nature, which contrasts with the…