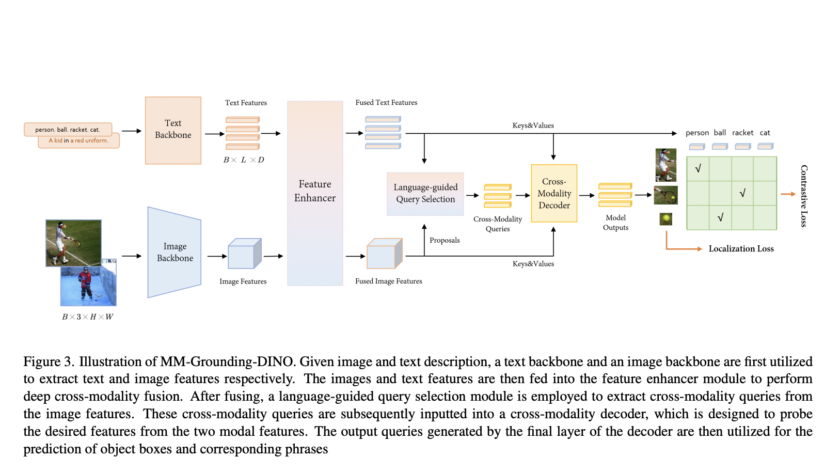
Object detection plays a vital role in multi-modal understanding systems, where images are input into models to generate proposals aligned with text. This process is crucial for state-of-the-art models handling Open-Vocabulary Detection (OVD), Phrase Grounding (PG), and Referring Expression Comprehension (REC). OVD models are trained on base categories in zero-shot scenarios but must predict both…