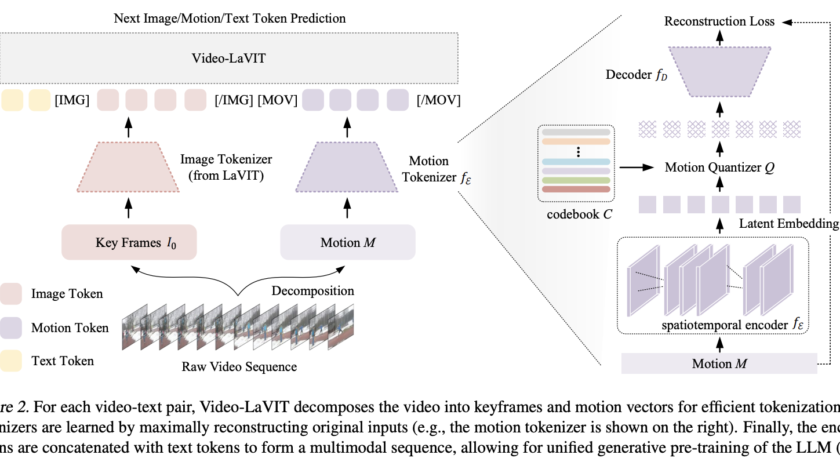
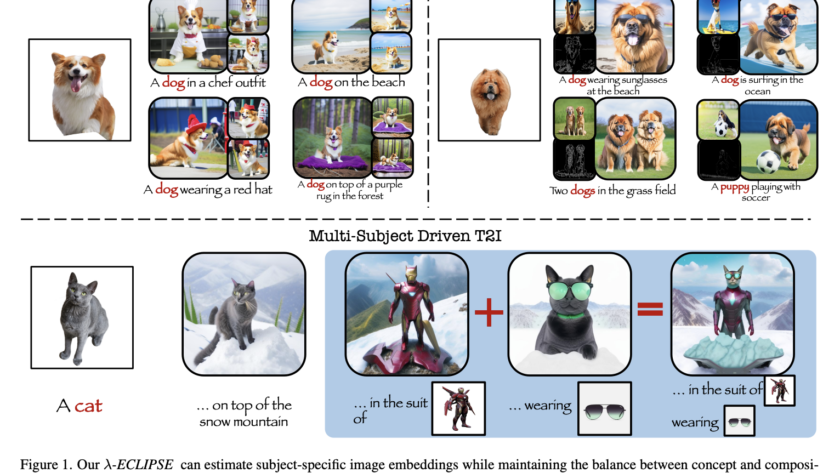
There has been a recent uptick in the development of general-purpose multimodal AI assistants capable of following visual and written directions, thanks to the remarkable success of Large Language Models (LLMs). By utilizing the impressive reasoning capabilities of LLMs and information found in huge alignment corpus (such as image-text pairs), they demonstrate the immense potential…