Transformer models are crucial in machine learning for language and vision processing tasks. Transformers, renowned for their effectiveness in sequential data handling, play a pivotal role in natural language processing and computer vision. They are designed to process input data in parallel, making them highly efficient for large datasets. Regardless, traditional Transformer architectures must improve their ability to manage long-term dependencies within sequences, a critical aspect for understanding context in language and images.
The central challenge addressed in the current study is the efficient and effective modeling of long-term dependencies in sequential data. While adept at handling shorter sequences, traditional transformer models need help capturing extensive contextual relationships, primarily due to computational and memory constraints. This limitation becomes pronounced in tasks requiring understanding long-range dependencies, such as in complex sentence structures in language modeling or detailed image recognition in vision tasks, where the context may span across a wide range of input data.
Present methods to mitigate these limitations include various memory-based approaches and specialized attention mechanisms. However, these solutions often increase computational complexity or fail to capture sparse, long-range dependencies adequately. Techniques like memory caching and selective attention have been employed, but they either increase the model’s complexity or need to extend the model’s receptive field sufficiently. The existing landscape of solutions underscores the need for a more effective method to enhance Transformers’ ability to process long sequences without prohibitive computational costs.
Researchers from The Chinese University of Hong Kong, The University of Hong Kong, and Tencent Inc. propose an innovative approach called Cached Transformers, augmented with a Gated Recurrent Cache (GRC). This novel component is designed to enhance Transformers’ capability to handle long-term relationships in data. The GRC is a dynamic memory system that efficiently stores and updates token embeddings based on their relevance and historical significance. This system allows the Transformer to process the current input and draw on a rich, contextually relevant history, thereby significantly expanding its understanding of long-range dependencies.
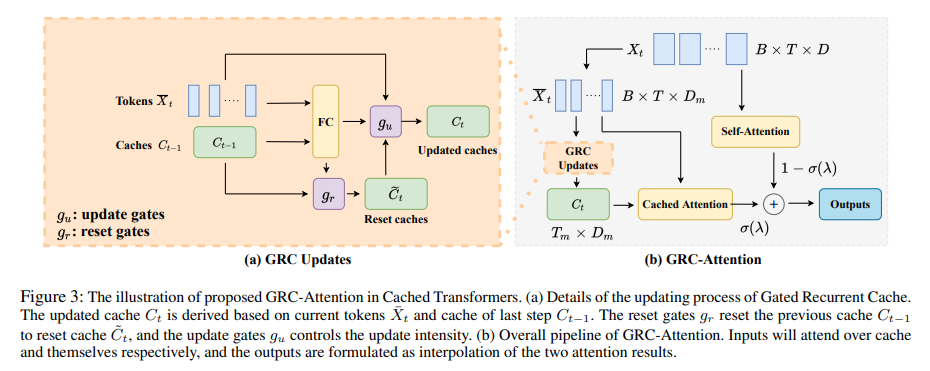
The GRC is a key innovation that dynamically updates a token embedding cache to represent historical data efficiently. This adaptive caching mechanism enables the Transformer model to attend to a combination of current and accumulated information, significantly extending its ability to process long-range dependencies. The GRC maintains a balance between the need to store relevant historical data and the computational efficiency, thereby addressing the traditional Transformer models’ limitations in handling long sequential data.
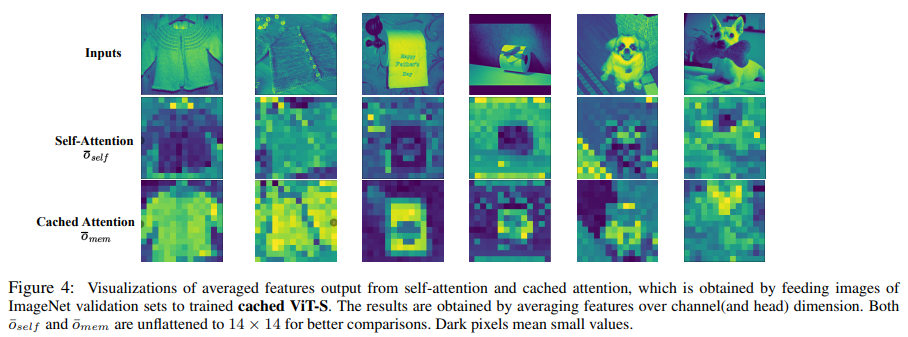
Integrating Cached Transformers with GRC demonstrates notable improvements in language and vision tasks. For instance, in language modeling, the enhanced Transformer models equipped with GRC outperform traditional models, achieving lower perplexity and higher accuracy in complex tasks like machine translation. This improvement is attributed to the GRC’s efficient handling of long-range dependencies, providing a more comprehensive context for each input sequence. Such advancements indicate a significant step forward in the capabilities of Transformer models.
In conclusion, the research can be summarized in the following points:
- The problem of modeling long-term dependencies in sequential data is effectively tackled by Cached Transformers with GRC.
- The GRC mechanism significantly enhances the Transformers’ ability to understand and process extended sequences, thus improving performance in both language and vision tasks.
- This advancement represents a notable leap in machine learning, particularly in how Transformer models handle context and dependencies over long data sequences, setting a new standard for future developments in the field.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to join our 35k+ ML SubReddit, 41k+ Facebook Community, Discord Channel, and Email Newsletter, where we share the latest AI research news, cool AI projects, and more.
If you like our work, you will love our newsletter..
Hello, My name is Adnan Hassan. I am a consulting intern at Marktechpost and soon to be a management trainee at American Express. I am currently pursuing a dual degree at the Indian Institute of Technology, Kharagpur. I am passionate about technology and want to create new products that make a difference.