The efficient training of vision models is still a major challenge in AI because Transformer-based models suffer from computational bottlenecks due to the quadratic complexity of self-attention mechanisms. Also, the ViTs, although extremely promising results on hard vision tasks, require extensive computational and memory resources, making them impossible to use under real-time or resource-constrained conditions. Recently, SSMs have gained more interest due to their scalability regarding handling long-sequence data. However, even state-of-the-art SSM-based models such as Vision Mamba require very high memory and computation training costs. Efficiently overcoming these limitations will greatly expand the application of AI vision models within areas that demand a delicate balance between accuracy and computational efficiency, such as in autonomous systems or medical imaging.
The current work to enhance the efficiency in the vision models is being carried out mainly for the ViTs, with two such classical techniques. Token pruning is performed to remove several tokens that carry less information, while token merging is carried out to combine the tokens retaining the essence with reduced complexity. Although those methods improve the computational efficiency of Transformer models, they perform less effectively for SSMs, which need to keep long-range dependencies without sacrificing the efficiency of processing sequential data. Besides that, most traditional token fusion techniques perform uniform fusion over all layers, which causes noticeable accuracy loss and may degrade the performance of SSM-based vision models in critical applications. Therefore, these methods failed to provide the models with a desirable balance between accuracy and efficiency, such as Vim.
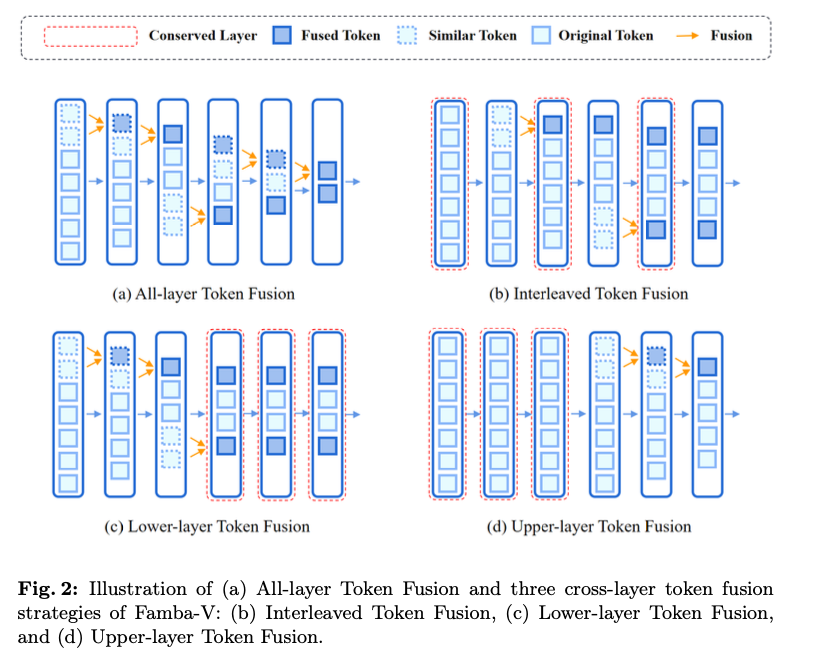
Researchers from Ohio State University introduce Famba-V, a targeted, cross-layer token fusion strategy for Vision Mamba, which overcomes limitations by selectively applying token fusion across specific layers based on their contribution to efficiency and accuracy. Token merging and detection of similar tokens in Famba-V rely on cosine similarity. Three fusion strategies are followed: Interleaved, Lower-layer, and Upper-layer Token Fusion. These strategies target different layers of the Vim model in pursuit of the optimum trade-off between resource efficiency and performance. As an illustration, the Interleaved strategy applies fusion to every other layer. In this case, after a relatively small loss in accuracy, some efficiency gains are won. Another, the Upper-layer strategy, will reduce interference with the initial layers of data processing. This architecture gives the best performance for Famba-V, while it has huge computational and memory efficiency suitable for resource-limited applications.
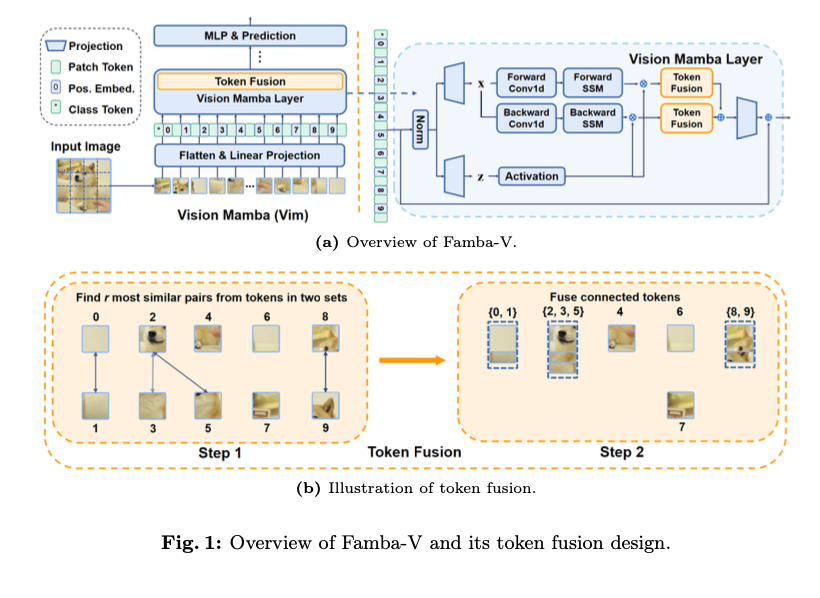
CIFAR-100 dataset benchmarking was done by Vim-Ti and Vim-S variants of Vim architecture, having 7 million and 26 million parameters respectively. This is done in Famba-V by measuring the token similarity in each chosen layer, averaging them out for similar token pairs. Every strategy was designed to have approximately equal numbers of reduced tokens across different strategies so that comparisons are fair. Experiments were done on the NVIDIA A100 GPU, and a typical training configuration with some standard augmentation-random cropping and label smoothing with mix-up was conducive to robustness in results. By providing various fusion strategies, Famba-V enables the user to choose an appropriate trade-off between accuracy and efficiency regarding their demands on computation.
The application of Famba-V to CIFAR-100 has shown an effective balance between efficiency and accuracy across the models of Vim: for all variants of the models of Vim, training time and memory usage have been drastically reduced, while maintaining accuracy values near the model variants that are not token-fused. The token fusion strategy at the Upper-layer on Vim-S maintained a Top-1 accuracy of 75.2%, which is a minimal reduction from the non-fused baseline of 76.9%, yet significantly economizes on memory usage, thus showing the large potential of the strategy in sustaining model integrity with much better efficiency. Likewise, the Interleaved fusion strategy on Vim-Ti achieved a Top-1 accuracy of 67.0% and reduced training time to less than four hours, once more demonstrating the ability of Famba-V to tailor its configuration to best exploit given resources. This ease in adapting to computational constraints with outstanding performance makes Famba-V practical for such applications that require efficiency with reliability in such resource-constrained settings.
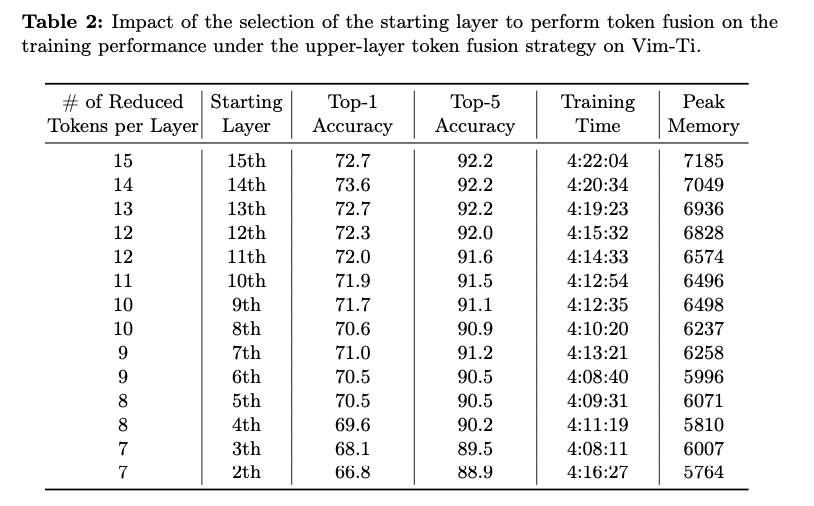
In conclusion, Famba-V’s cross-layer token fusion framework presents a substantial advancement in training efficiency for Vision Mamba models. Famba-V achieves a flexible balance between accuracy and efficiency by implementing three cross-layer strategies: Interleaved, Lower-layer, and Upper-layer Fusion. It notably reduces training time and memory consumption on CIFAR-100 without sacrificing model robustness. The adaptability in design makes Famba-V of particular value for real-world vision tasks; hence, extending the application of SSM-based models in resource-constrained environments. In addition, further studies can be conducted to see how Famba-V can be integrated with other strategies to enhance the efficiency of finding an even better optimization of SSM-based models for vision tasks.
Check out the Paper and GitHub. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter and join our Telegram Channel and LinkedIn Group. If you like our work, you will love our newsletter.. Don’t Forget to join our 55k+ ML SubReddit.
[Upcoming Live Webinar- Oct 29, 2024] The Best Platform for Serving Fine-Tuned Models: Predibase Inference Engine (Promoted)
Aswin AK is a consulting intern at MarkTechPost. He is pursuing his Dual Degree at the Indian Institute of Technology, Kharagpur. He is passionate about data science and machine learning, bringing a strong academic background and hands-on experience in solving real-life cross-domain challenges.