Text-to-image diffusion models have made significant strides in generating complex and faithful images from input conditions. Among these, Diffusion Transformers Models (DiTs) have emerged as particularly powerful, with OpenAI’s SoRA being a notable application. DiTs, constructed by stacking multiple transformer blocks, utilize the scaling properties of transformers to achieve enhanced performance through flexible parameter expansion. While DiTs outperform UNet-based diffusion models in image quality, they face deployment challenges due to their large parameter count and high computational complexity. For instance, generating a 256 × 256 resolution image using the DiT XL/2 model requires over 17 seconds and 105 Gflops on an NVIDIA A100 GPU. This computational demand makes deploying DiTs on edge devices with limited resources impractical, prompting researchers to explore efficient deployment methods, particularly through model quantization.
VQ4DiT: Efficient Post-Training Vector Quantization for Diffusion Transformers
Text-to-image diffusion models have made significant strides in generating complex and faithful images from input conditions. Among these, Diffusion Transformers Models (DiTs) have emerged as particularly powerful, with OpenAI’s SoRA being a notable application. DiTs, constructed by stacking multiple transformer blocks, utilize the scaling properties of transformers to achieve enhanced performance through flexible parameter expansion. While DiTs outperform UNet-based diffusion models in image quality, they face deployment challenges due to their large parameter count and high computational complexity. For instance, generating a 256 × 256 resolution image using the DiT XL/2 model requires over 17 seconds and 105 Gflops on an NVIDIA A100 GPU. This computational demand makes deploying DiTs on edge devices with limited resources impractical, prompting researchers to explore efficient deployment methods, particularly through model quantization.
Prior attempts to address the deployment challenges of diffusion models have primarily focused on model quantization techniques. Post-training quantization (PTQ) has been widely used due to its rapid implementation without extensive fine-tuning. Vector quantization (VQ) has shown promise in compressing CNN models to extremely low bit-widths. However, these methods face limitations when applied to DiTs. PTQ methods significantly reduce model accuracy at very low bit-widths, such as 2-bit quantization. Traditional VQ methods only calibrate the codebook without adjusting assignments, leading to suboptimal outcomes due to incorrect assignment of weight sub-vectors and inconsistent gradients to the codebook.
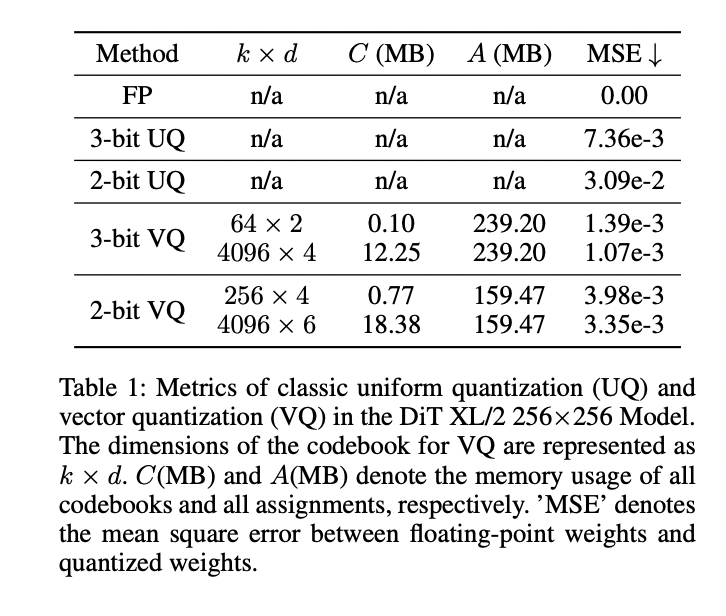
The application of classic uniform quantization (UQ) and VQ to the DiT XL/2 model reveals significant challenges in achieving optimal performance at extremely low bit-widths. While VQ outperforms UQ in terms of quantization error, it still faces issues with performance degradation, especially at 2-bit and 3-bit quantization levels. The trade-off between codebook size, memory usage, and quantization error presents a complex optimization problem. Fine-tuning quantized DiTs on large datasets like ImageNet is computationally intensive and time-consuming. Also, the accumulation of quantization errors in these large-scale models leads to suboptimal results, even after fine-tuning. The key issue lies in the conflicting gradients for sub-vectors with the same assignment, hindering proper codeword updates.
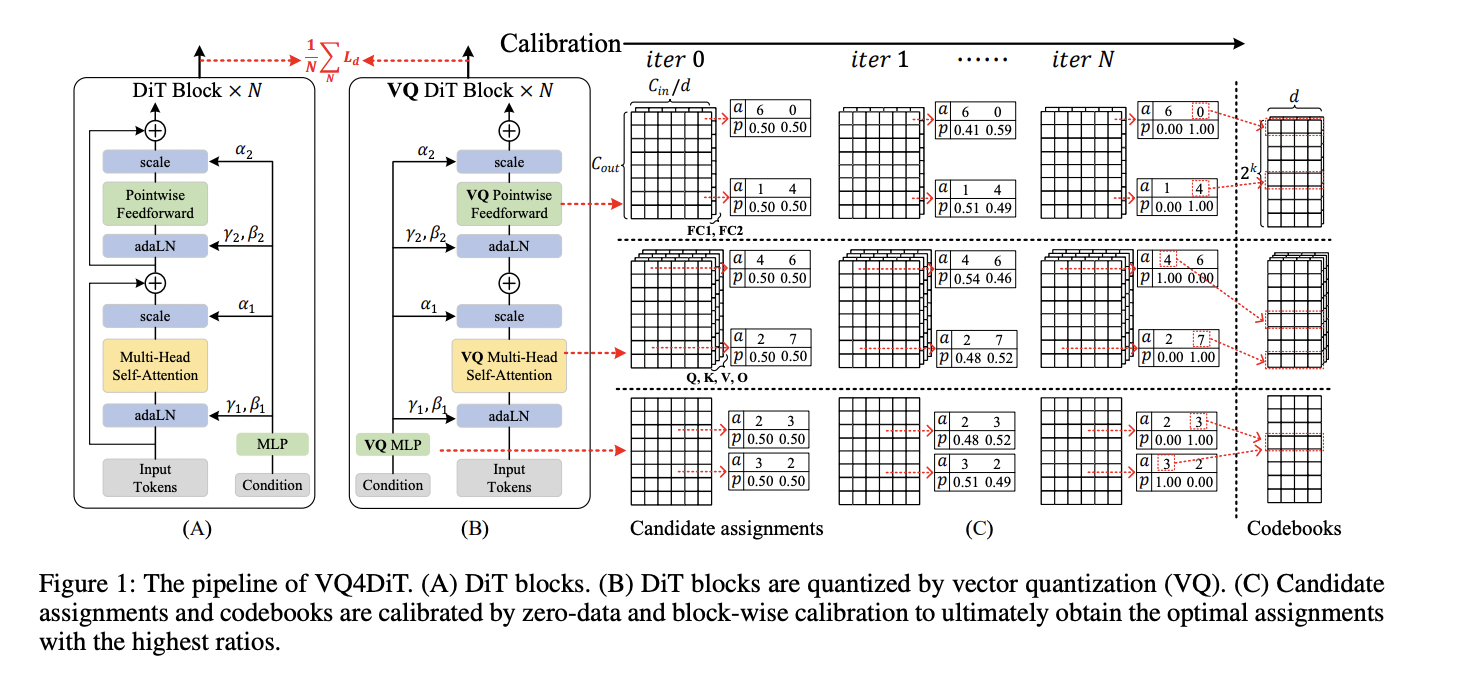
To overcome the limitations of existing quantization methods, researchers from Zhejiang University and vivo Mobile Communication Co., Ltd have developed Efficient Post-Training Vector Quantization for Diffusion Transformers (VQ4DiT). This robust approach efficiently and accurately vector quantizes DiTs without requiring a calibration dataset. VQ4DiT decomposes the weights of each layer into a codebook and candidate assignment sets, initializing each candidate assignment with an equal ratio. It then employs a zero-data and block-wise calibration strategy to simultaneously calibrate codebooks and candidate assignment sets. This method minimizes the mean square error between the outputs of floating-point and quantized models at each timestep and DiT block, ensuring the quantized model maintains performance similar to its floating-point counterpart while avoiding calibration collapse due to cumulative quantization errors.

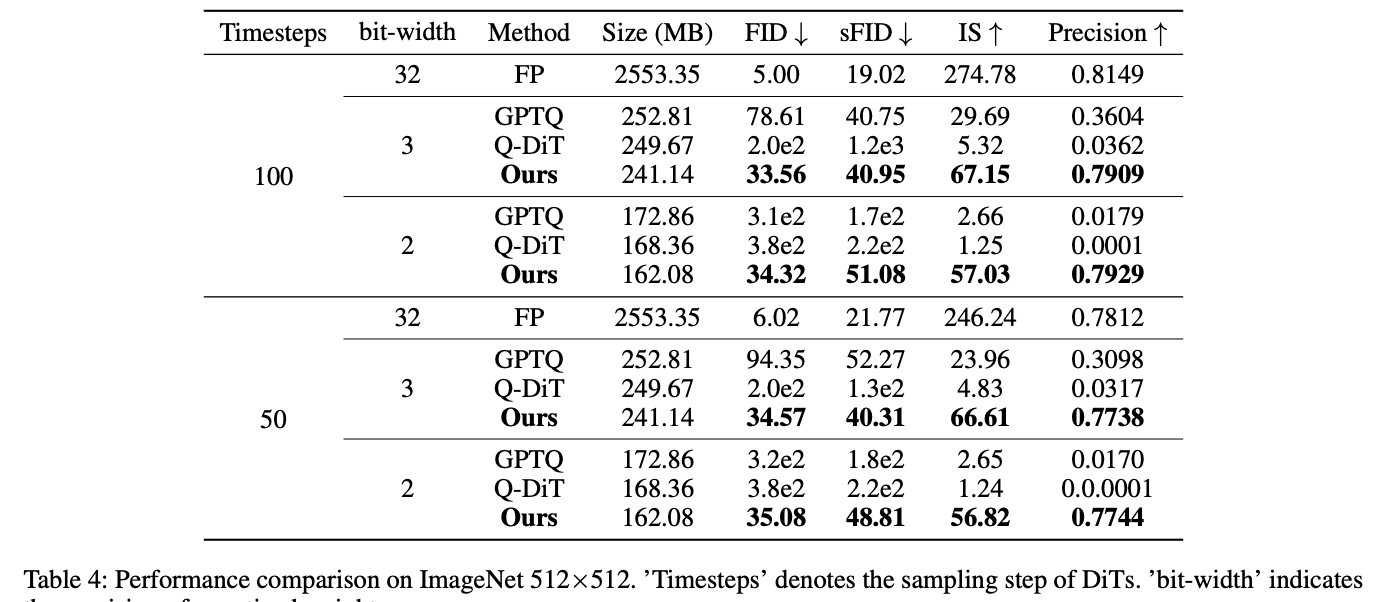
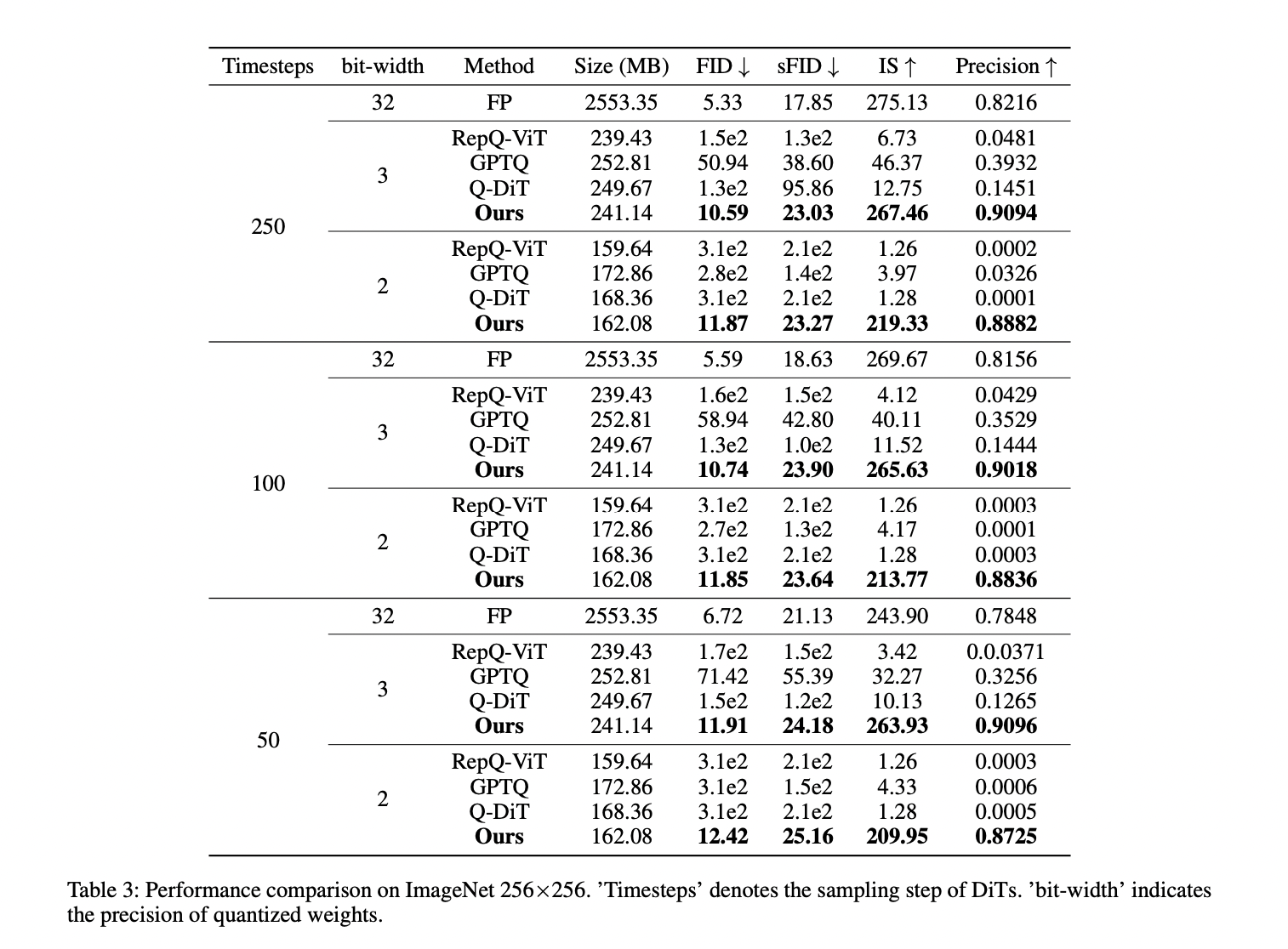
The DiT XL/2 model, quantized using VQ4DiT, demonstrates superior performance on ImageNet 256×256 and 512×512 datasets across various sample timesteps and weight bit-widths. At 256×256 resolution, VQ4DiT outperforms other methods, including RepQ-ViT, GPTQ, and Q-DiT, especially under 3-bit quantization. VQ4DiT maintains performance close to the floating-point model, with minimal increases in FID and decreases in IS. At 2-bit quantization, where other algorithms collapse, VQ4DiT continues to generate high-quality images with only a slight decrease in precision. Similar results are observed at 512×512 resolution, indicating VQ4DiT’s capability to produce high-quality, high-resolution images with minimal memory usage, making it ideal for deploying DiTs on edge devices.
This study presents VQ4DiT, a unique and robust post-training vector quantization method for DiTs, that addresses key challenges in efficient quantization. By balancing codebook size with quantization error and resolving inconsistent gradient directions, VQ4DiT achieves optimal assignments and codebooks through a zero-data and block-wise calibration process. This innovative approach calculates candidate assignment sets for each sub-vector and progressively calibrates each layer’s codebook and assignments. Experimental results demonstrate VQ4DiT’s effectiveness in quantizing DiT weights to 2-bit precision while preserving high-quality image generation capabilities. This advancement significantly enhances the potential for deploying DiTs on resource-constrained edge devices, opening new possibilities for efficient, high-quality image generation in various applications.
Prior attempts to address the deployment challenges of diffusion models have primarily focused on model quantization techniques. Post-training quantization (PTQ) has been widely used due to its rapid implementation without extensive fine-tuning. Vector quantization (VQ) has shown promise in compressing CNN models to extremely low bit-widths. However, these methods face limitations when applied to DiTs. PTQ methods significantly reduce model accuracy at very low bit-widths, such as 2-bit quantization. Traditional VQ methods only calibrate the codebook without adjusting assignments, leading to suboptimal outcomes due to incorrect assignment of weight sub-vectors and inconsistent gradients to the codebook.
The application of classic uniform quantization (UQ) and VQ to the DiT XL/2 model reveals significant challenges in achieving optimal performance at extremely low bit widths. While VQ outperforms UQ in terms of quantization error, it still faces issues with performance degradation, especially at 2-bit and 3-bit quantization levels. The trade-off between codebook size, memory usage, and quantization error presents a complex optimization problem. Fine-tuning quantized DiTs on large datasets like ImageNet is computationally intensive and time-consuming. Also, the accumulation of quantization errors in these large-scale models leads to suboptimal results, even after fine-tuning. The key issue lies in the conflicting gradients for sub-vectors with the same assignment, hindering proper codeword updates.
To overcome the limitations of existing quantization methods, researchers from Zhejiang University and vivo Mobile Communication Co., Ltd have developed Efficient Post-Training Vector Quantization for Diffusion Transformers (VQ4DiT). This robust approach efficiently and accurately vector quantizes DiTs without requiring a calibration dataset. VQ4DiT decomposes the weights of each layer into a codebook and candidate assignment sets, initializing each candidate assignment with an equal ratio. It then employs a zero-data and block-wise calibration strategy to simultaneously calibrate codebooks and candidate assignment sets. This method minimizes the mean square error between the outputs of floating-point and quantized models at each timestep and DiT block, ensuring the quantized model maintains performance similar to its floating-point counterpart while avoiding calibration collapse due to cumulative quantization errors.
The DiT XL/2 model, quantized using VQ4DiT, demonstrates superior performance on ImageNet 256×256 and 512×512 datasets across various sample timesteps and weight bit-widths. At 256×256 resolution, VQ4DiT outperforms other methods, including RepQ-ViT, GPTQ, and Q-DiT, especially under 3-bit quantization. VQ4DiT maintains performance close to the floating-point model, with minimal increases in FID and decreases in IS. At 2-bit quantization, where other algorithms collapse, VQ4DiT continues to generate high-quality images with only a slight decrease in precision. Similar results are observed at 512×512 resolution, indicating VQ4DiT’s capability to produce high-quality, high-resolution images with minimal memory usage, making it ideal for deploying DiTs on edge devices.
This study presents VQ4DiT, a unique and robust post-training vector quantization method for DiTs, that addresses key challenges in efficient quantization. By balancing codebook size with quantization error and resolving inconsistent gradient directions, VQ4DiT achieves optimal assignments and codebooks through a zero-data and block-wise calibration process. This innovative approach calculates candidate assignment sets for each sub-vector and progressively calibrates each layer’s codebook and assignments. Experimental results demonstrate VQ4DiT’s effectiveness in quantizing DiT weights to 2-bit precision while preserving high-quality image generation capabilities. This advancement significantly enhances the potential for deploying DiTs on resource-constrained edge devices, opening new possibilities for efficient, high-quality image generation in various applications.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter and LinkedIn. Join our Telegram Channel.
If you like our work, you will love our newsletter..
Don’t Forget to join our 50k+ ML SubReddit
Asjad is an intern consultant at Marktechpost. He is persuing B.Tech in mechanical engineering at the Indian Institute of Technology, Kharagpur. Asjad is a Machine learning and deep learning enthusiast who is always researching the applications of machine learning in healthcare.