

Image by Author
Data orchestration has become a critical component of modern data engineering, allowing teams to streamline and automate their data workflows. While Apache Airflow is a widely used tool known for its flexibility and strong community support. However, there are several other alternatives that offer unique features and benefits.
In this blog post, we will discuss five alternatives to manage workflows: Prefect, Dagster, Luigi, Mage AI, and Kedro. These tools can be used for any field, not just limited to data engineering. By understanding these tools, you’ll be able to choose the one that best suits your data and machine learning workflow needs.
Prefect is an open-source tool for building and managing workflows, providing observability and triaging capabilities. You can build interactive workflow applications using a few lines of Python code.
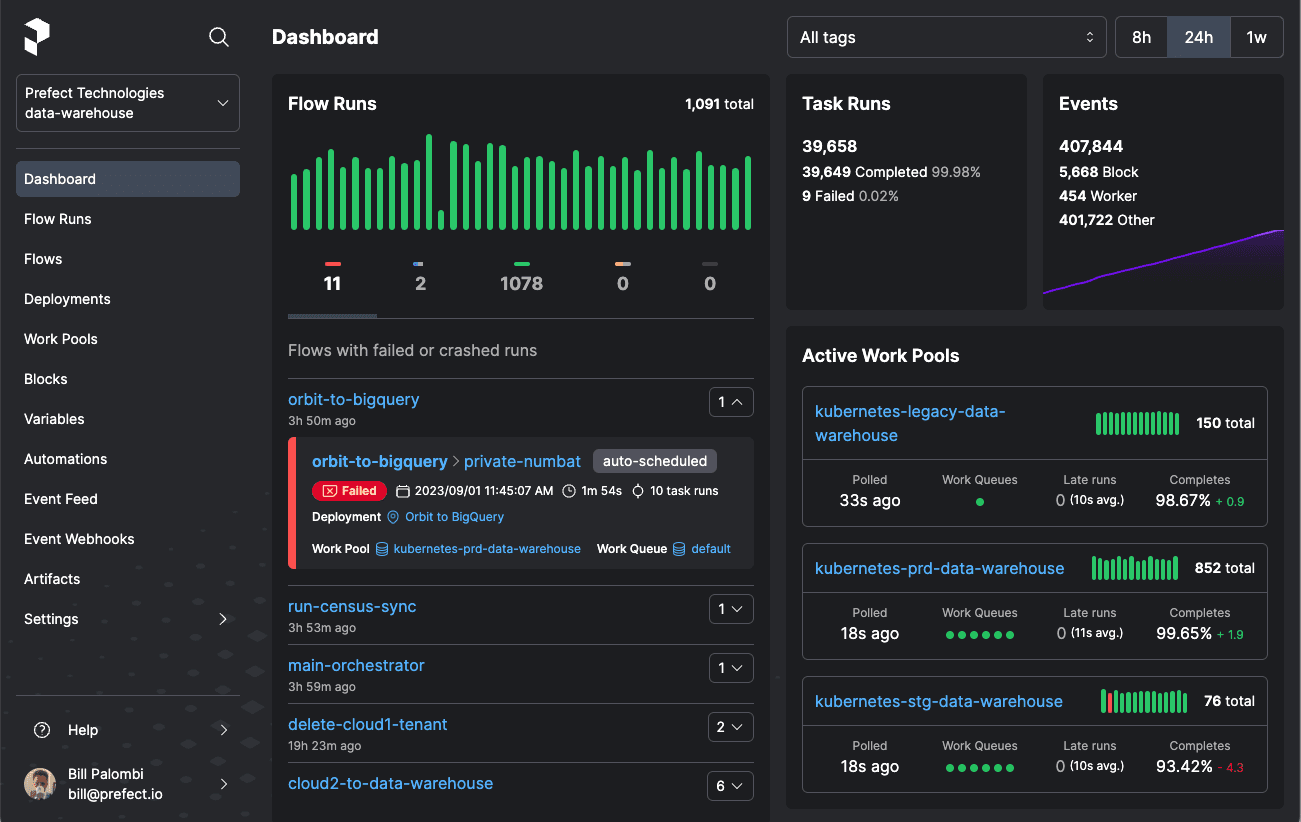
Prefect offers a hybrid execution model that allows workflows to run in the cloud or on-premises, providing users with greater control over their data operations. Its intuitive UI and rich API enable easy monitoring and troubleshooting of data workflows.
Dagster is a powerful, open-source data pipeline orchestrator that simplifies the development, maintenance, and observation of data assets throughout their entire lifecycle. Built for cloud-native environments, Dagster offers integrated data lineage, observability, and a user-friendly development environment, making it a popular choice for data engineers, data scientists, and machine learning engineers.
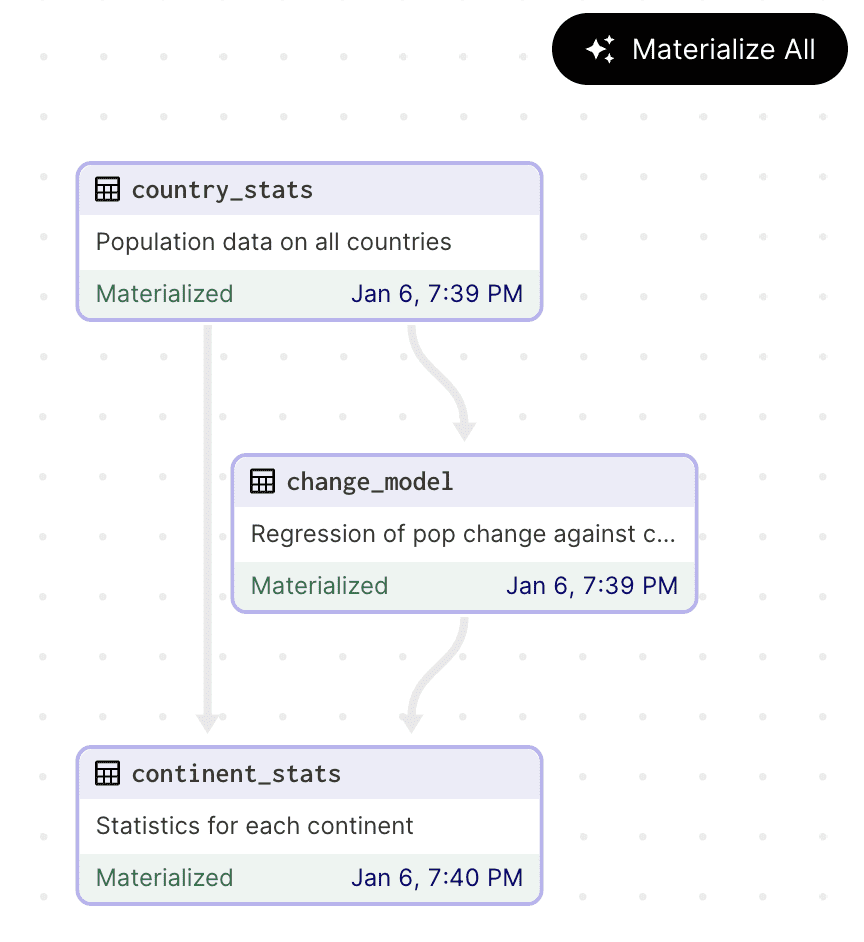
Dagster is an open-source data orchestration system that allows users to define their data assets as Python functions. Once defined, Dagster manages and executes these functions based on a user-defined schedule or in response to specific events. Dagster can be used at every stage of the data development lifecycle, from local development and unit testing to integration testing, staging environments, and production.
Luigi, developed by Spotify, is a Python-based framework for building complex pipelines of batch jobs. It handles dependency resolution, workflow management, visualization, and more, focusing on reliability and scalability.
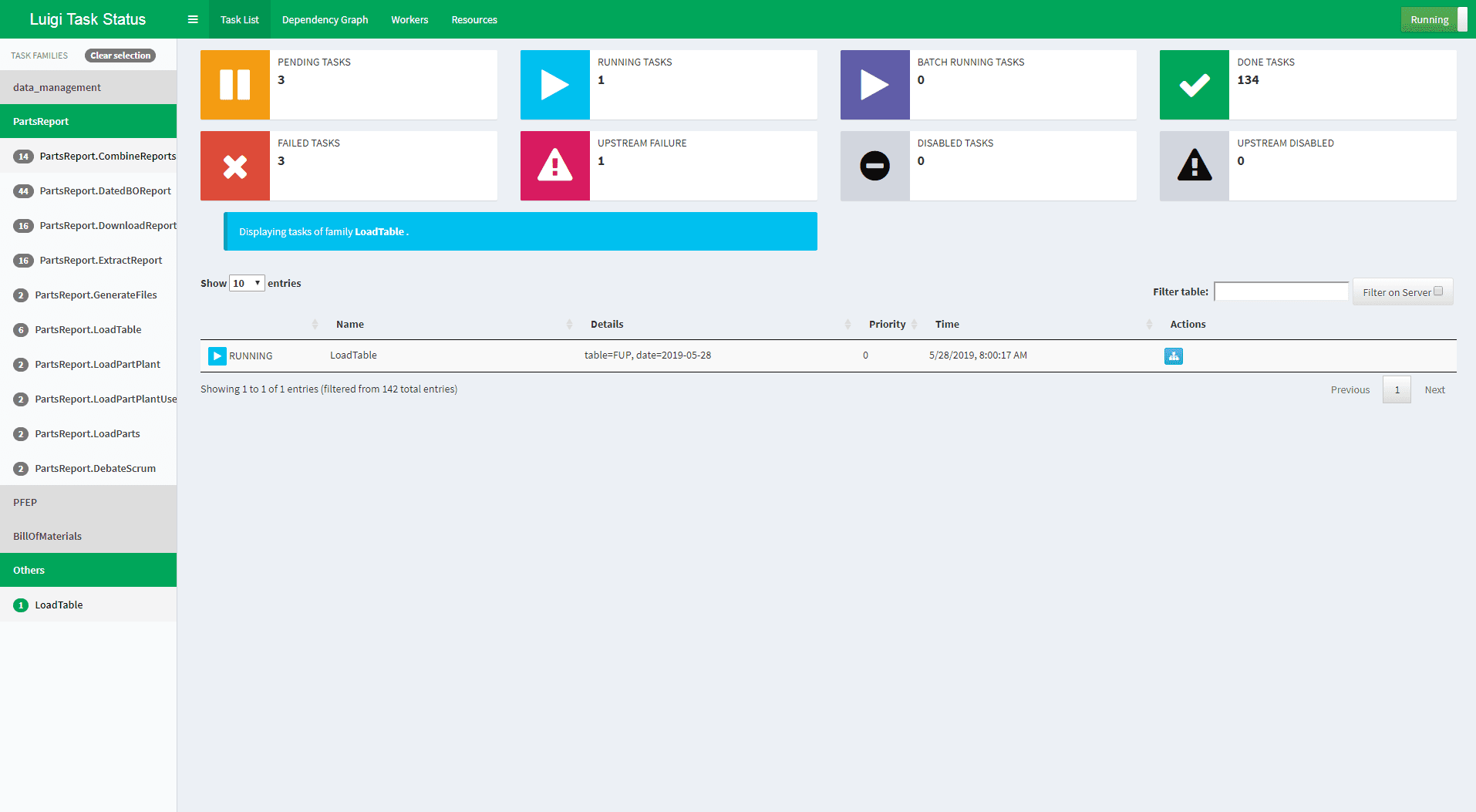
Luigi is a powerful tool that excels in managing task dependencies, ensuring that tasks are executed in the correct order and only if their dependencies are met. It is particularly suitable for workflows that involve a mix of Hadoop jobs, Python scripts, and other batch processes.
Luigi provides an infrastructure that supports various operations, including recommendations, toplists, A/B test analysis, external reports, internal dashboards, etc.
Mage AI is a newer entrant in the data orchestration space, offering a hybrid framework for transforming and integrating data, combining the flexibility of notebooks with the rigor of modular code. It is designed to streamline the process of extracting, transforming, and loading data, enabling users to work with data in a more efficient and user-friendly manner.
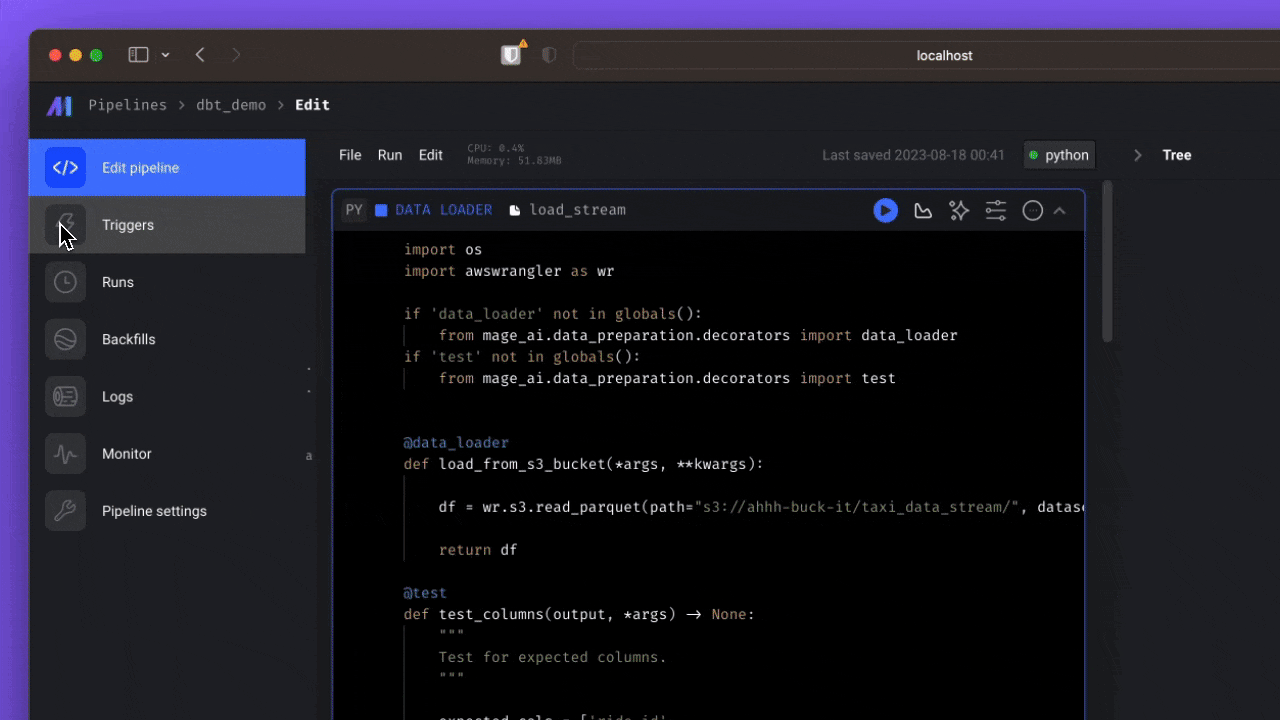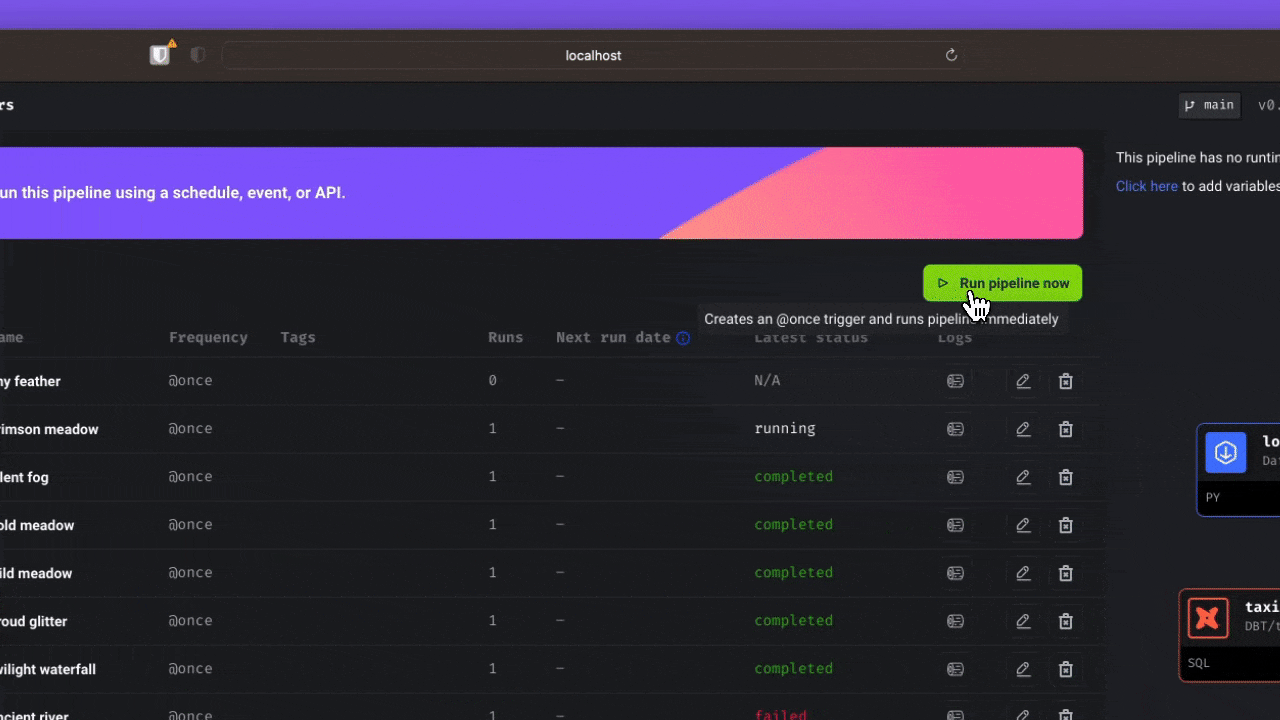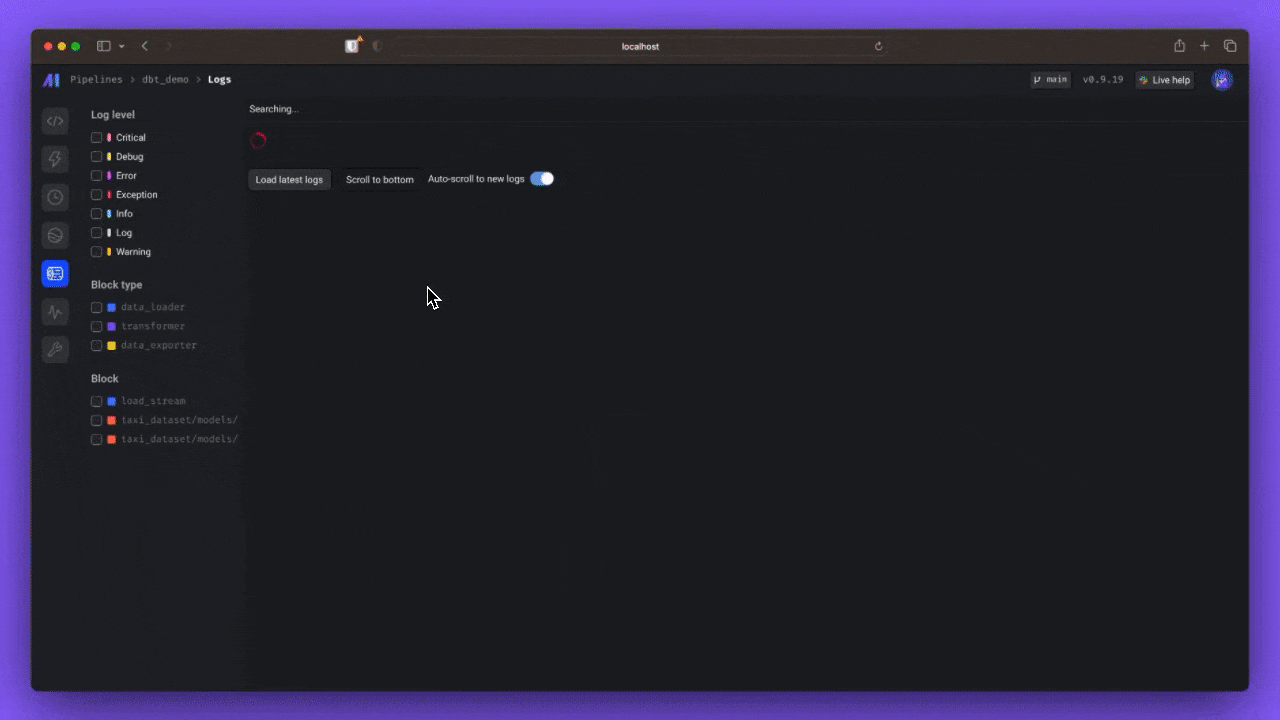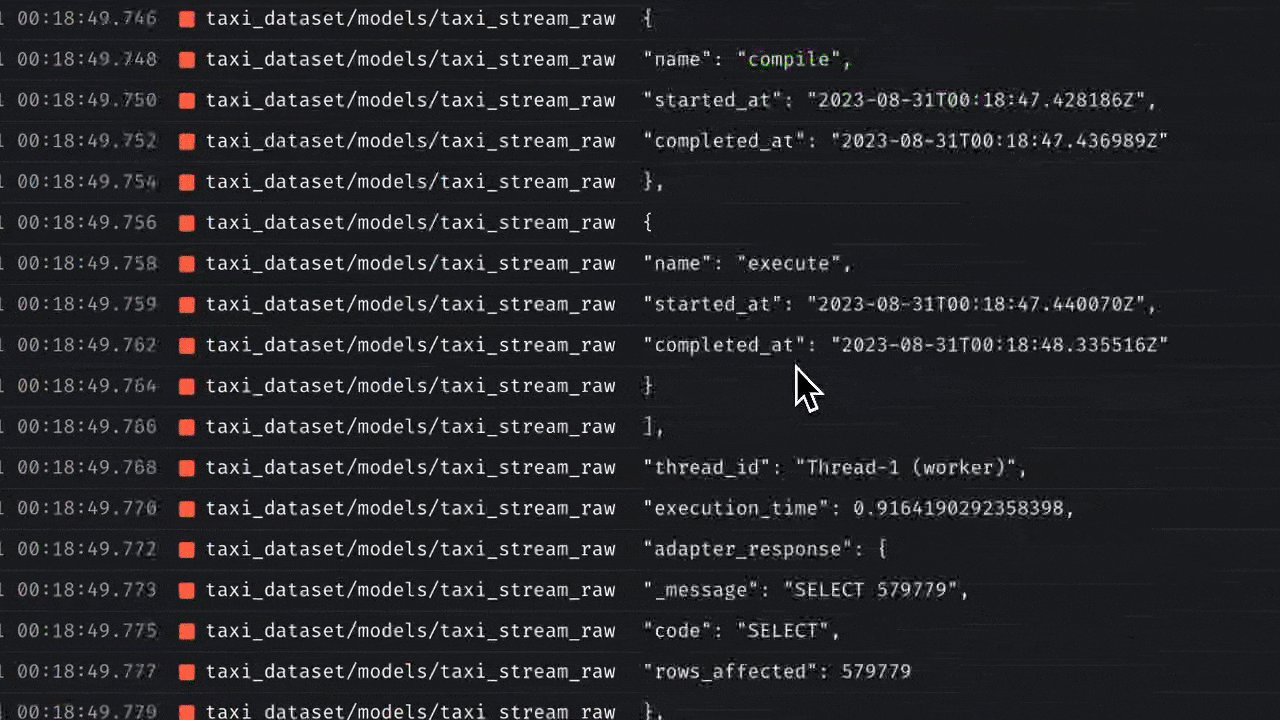
Mage AI provides a simple developer experience, supports multiple programming languages, and enables collaborative development. Its built-in monitoring, alerting, and observability features make it well-suited for large-scale, complex data pipelines. Mage AI also supports dbt for building, running, and managing dbt models.
Kedro is a Python framework that provides a standardized way to build data and machine learning pipelines. It uses software engineering best practices to help you create data engineering and data science pipelines that are reproducible, maintainable, and modular.
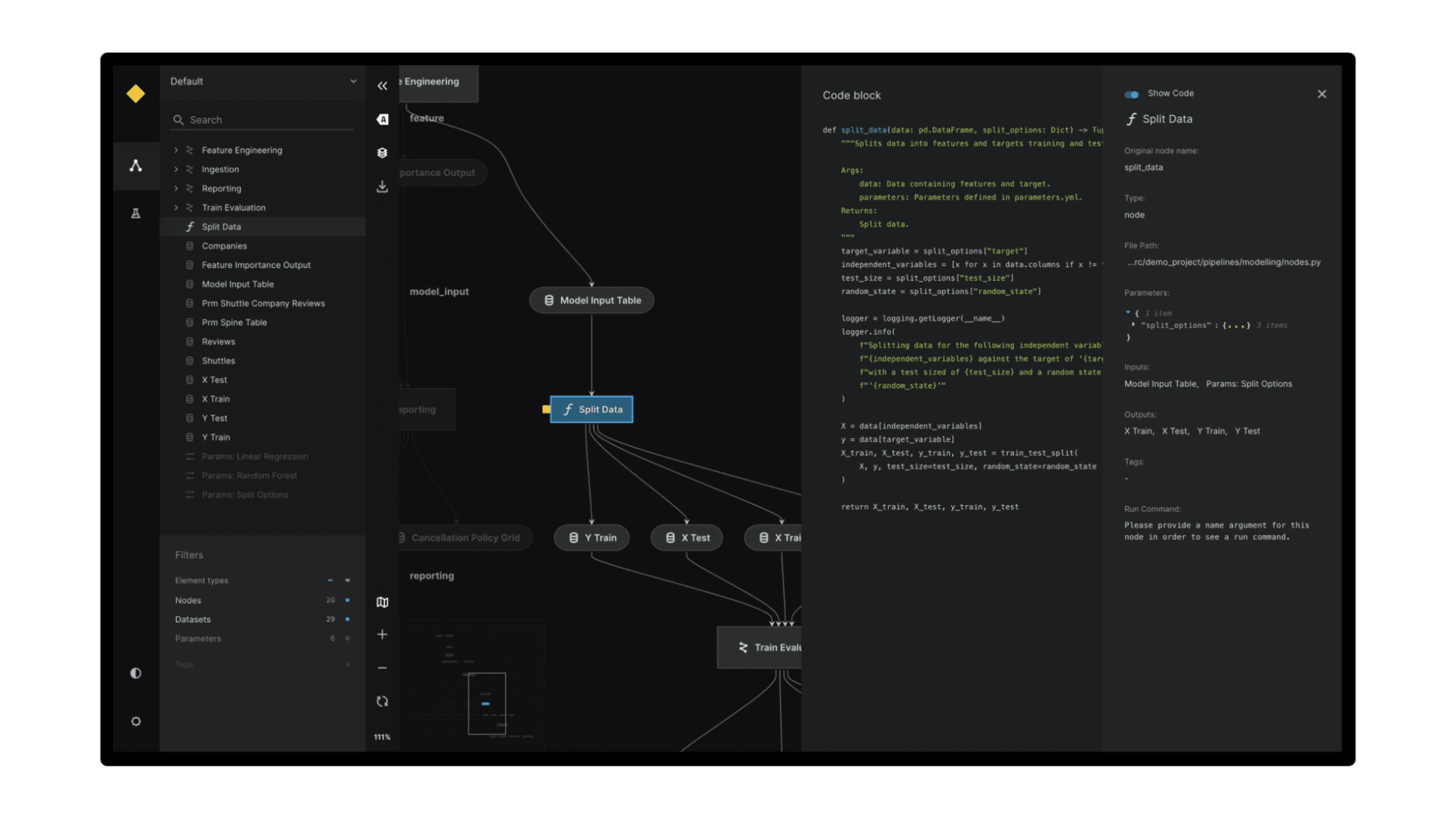
Kedro provides a standardized project template, data connectors, pipeline abstraction, coding standards, and flexible deployment options, which simplify the process of building, testing, and deploying data science projects. By using Kedro, data scientists can ensure a consistent and organized project structure, easily manage data and model versioning, automate pipeline dependencies, and deploy projects on various platforms.
While Apache Airflow continues to be a popular tool for data orchestration, the alternatives presented here offer a range of features and benefits that may better suit certain projects or team preferences. Whether you prioritize simplicity, code-centric design, or the integration of machine learning workflows, there is likely an alternative that meets your needs. By exploring these options, teams can find the right tool to enhance their data operations and drive more value from their data initiatives.
If you are new to the field of Data Engineering, consider taking the Data Engineering Professional Course to become job-ready and start earning $300K/Yr.
Abid Ali Awan (@1abidaliawan) is a certified data scientist professional who loves building machine learning models. Currently, he is focusing on content creation and writing technical blogs on machine learning and data science technologies. Abid holds a Master’s degree in Technology Management and a bachelor’s degree in Telecommunication Engineering. His vision is to build an AI product using a graph neural network for students struggling with mental illness.

