

Image from Editor
As a solid ex-chess player (junior champion, ELO 2000+) and NLP data scientist, I have been planning to write this article for a while.
The first time I heard about ChatGPT’s ability to play chess, was from one of my colleagues. Ph.D. and a very smart guy. He sent me the link to the webpage where you can play against ChatGPT as he thought. Unfortunately, it wasn’t pure ChatGPT, it was some other chess engine under the hood. He was deceived. You can still try it here: https://parrotchess.com/
For the purpose of this article, I played 2 games against the ChatGPT. Here is how we started:

Let’s take a look at what happened.
Quick chess notation course / reminder (can be skipped):
K = king, Q = queen, R = rock, B = Bishop, N = knight, 0–0 = Castling king’s side. 0–0–0 = Castling queen’s side, x = taking the piece. For pawns, we just write the square it lands, except when the pawn captures. In that case, we write the letter of the square where the pawn was before, and the letter and the number of the square on which it goes after taking the other piece. For example, exd4.
Nikola Greb vs. ChatGPT 4, the 7th of January 2024
1. e4 e5 2. Nf3 Nc6 3. d4 exd4 4. Nxd4 Nf6 5. Nc3 Bb4 6. Nxc6 bxc6 7. Bd3 O-O 8.
O-O d5 9. e5 Ne4 10. Nxe4 Bc5 11. Nxc5 Qe7 12. Qh5 g6 13. Qh6 f6 14. exf6 Qxf6
15. Bg5 Qf7 16. Rae1 Bf5 17. Re7 Qxe7 18. Bxe7 Rae8 19. Bxf8 Rxf8 20. Bxf5 Rf7
21. Re1 1-0
Until the move e5, ChatGPT 4 played like a very good chess player. We can say like GM. But when I played an imprecise, yet aggressive move (exd5 was the best move), it lost the common ground and blundered a pawn playing Ne4.

I took the knight with the knight (10. Nxe4) and the first hallucination occurred:


Bc5 was again a mistake, an obvious blunder. Since the rest of the game has no chess value, I will sum it up. ChatGPT 4 accused me of impossible moves, and ended up in hallucinations (proposing impossible moves), instead of surrendering the game.
Let’s see what happened in the game 2, where I played black pieces:
Nikola Greb vs. ChatGPT 4 (moves 1–9) and ChatGPT 3.5 (moves 10–12), the 7th of January 2024
1. e4 c5 2. Nf3 Nc6 3. d4 cxd4 4. Nxd4 e5 5. Nb5 d6 6. c4 f5 7. N1c3 Nf6 8. Bg5 Be7 9. Bd3 Nxe4 10. Bxe4 fxe4 11. Nxe4 Bxg5 12. Nec3 0–1
Until the position below, Chat GPT 4 played very well, building a significantly better position from which I would lose very quickly against a real grandmaster (even the candidate master) or chess engine. If white plays Bf6, black loses the pawn. Yet, ChatGPT played Bd3:

I responded with Ne4, and ChatGPT responded by switching to version 3.5 and playing Bxe4.
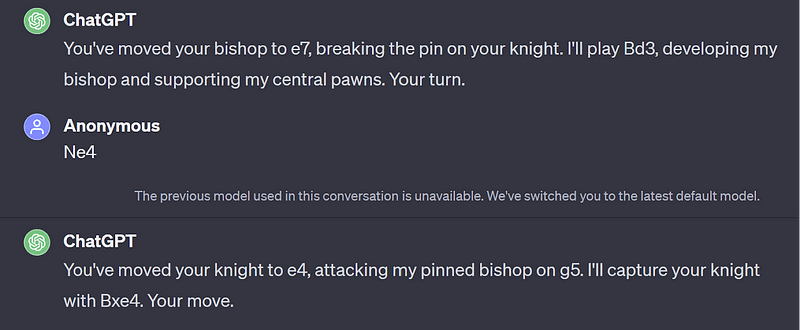
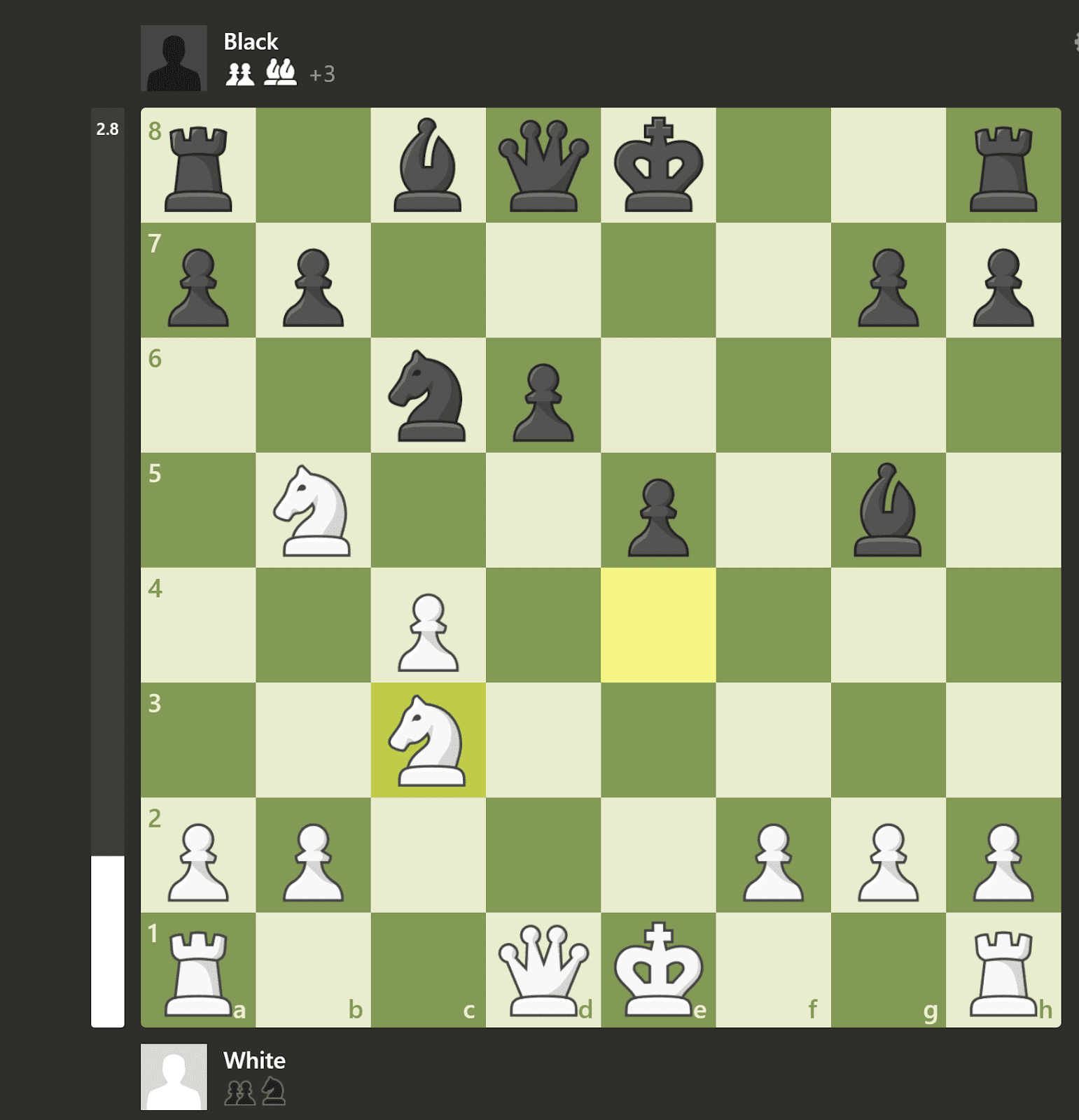
After a few moves, I had a decisive advantage (due to ChatGPT playing badly, not me doing something great) so I decided to test the opponent with an irregular move. I proposed Ne6 for black in this position:
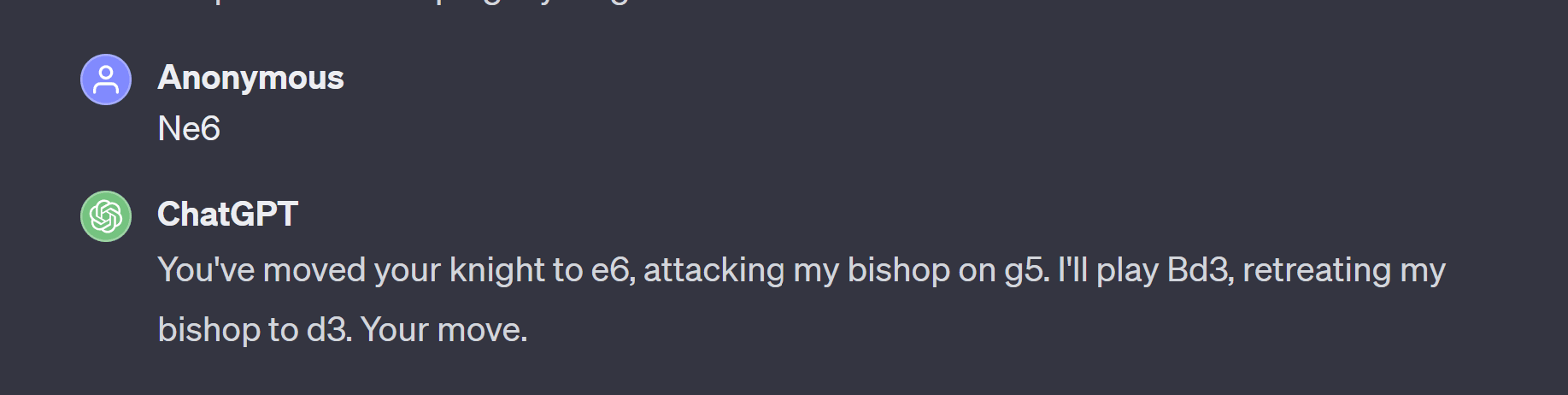
ChatGPT 3.5 wasn’t concerned with my move at all. On my hallucination, it responded with the new hallucination:
1. ChatGPT 4 is a very weak chess player, who plays very strangely — very good in early opening and terrible later. This is due to the increasing number of options as the chess game progresses. I would assess his overall ELO to be lower than 1500. Same for 3.5.
2. No implicit learning of rules happened —Chat GPT 4 still hallucinates in chess, and keeps hallucinating after the warning about the hallucination. This is something that can’t happen to the human.
3. More data would hardly solve the problem due to the edge cases like extra long endgames with repetition, or the possibility of playing unusual openings. LLMs simply aren’t built for playing chess, nor can evaluate the position. We already have AlphaZero and Stockfish for that.
4. Tracking the drop in the number of hallucinations that LLMs perform in playing chess might be a good path for understanding the potential of LLMs for logical reasoning. But paradox remains — LLM “knows” the rules of chess, yet hallucinates heavily ? the future of ML might be in LLM as the first-level agent that communicates to the user and then calls specialized agents with ML architectures adjusted for particular use cases.
5. LLMs have the potential to be useful in scientific research and show an interesting level of creativity combined with other machine learning algorithms. A recent example is FunSearch algorithm developed by DeepMind that combines LLM and evaluator to make discoveries in math. Contrary to chess where the evaluation of the position is the hardest task, many problems in mathematical sciences are “easy to evaluate, despite being typically hard to solve“.
I’m skeptical about building a well-performing chess-playing program based on transformers architecture, yet specialized LLM combined with external evaluation/chess program might be a good substitute for chess trainers soon. DeepMind created another cool model that is a good example of combining LLM and a specialized AI model — AlphaGeometry. It is very close to the Olympiad gold-medalist standard for geometry problems, advancing AI reasoning in mathematics.
6. LLMs are still fresh, the field is very young and there is too much hype that’s often backed up by misleading and wrong conclusions. As the authors of the ‘’Mathematical discoveries from program search with large language models’’ state:
“…to the best of our knowledge, this shows the first scientific discovery — a new piece of verifiable knowledge about a notorious scientific problem — using an LLM.” (accelerated preview was published on the 14 of December 2023).
7. The clip by Joe Rogan and 2 guests, titled ‘’I Wasn’t Afraid of AI Until I Learned This’’ was watched by 2,8 million of people on YouTube. One of the guests says that ChatGPT knows how to play chess which obviously isn’t the truth. I can just imagine how this kind of content influences people, especially uneducated or emotionally unstable individuals. Not in a good way, I’m sure about it.
To conclude, data science and software development is built on knowledge, precision and truth-seeking. As data scientists and developers, we should be people of truth and wisdom, calming down the madness produced by mass media about AI, not firing it up. Transformers, including ChatGPT, have great potential in language tasks, but they are still very far away from AGI. We should be optimistic but correct.
As a guideline, before dropping bombs, we should ask ourselves: What would happen if someone else would act upon my statements? What kind of world do you want to live in?
References & Further Exploration
- Mastering Chess and Shogi by Self-Play with a General Reinforcement Learning Algorithm: https://arxiv.org/pdf/1712.01815.pdf
- FunSearch: Making new discoveries in mathematical sciences using Large Language Models: https://deepmind.google/discover/blog/funsearch-making-new-discoveries-in-mathematical-sciences-using-large-language-models/
- Mathematical discoveries from program search with large language models: https://www.nature.com/articles/s41586-023-06924-6
- AlphaGeometry: An Olympiad-level AI system for geometry: https://deepmind.google/discover/blog/alphageometry-an-olympiad-level-ai-system-for-geometry/
- I Wasn’t Afraid of AI Until I Learned This: https://www.youtube.com/watch?v=2yd18z6iSyk&ab_channel=JREDailyClips
- How to play chess against ChatGPT (and why you probably shouldn’t): https://www.androidauthority.com/how-to-play-chess-with-chatgpt-3330016/
- Can Chat GPT Play chess?: https://towardsdatascience.com/can-chat-gpt-play-chess-4c44210d43e4
- How good is ChatGPT at playing chess? (Spoiler: you’ll be impressed): https://medium.com/@ivanreznikov/how-good-is-chatgpt-at-playing-chess-spoiler-youll-be-impressed-35b2d3ac024a
- Full conversation with ChatGPT: https://chat.openai.com/share/a1ff82b5-6210-4f7b-807c-220052de232c
- Mastering Chess and Shogi by Self-Play with a General Reinforcement Learning Algorithm: https://arxiv.org/pdf/1712.01815.pdf
Nikola Greb has been coding for more than four years, and for the past two years, he specialized in NLP. Before turning to data science, he was successful in sales, HR, writing, and chess.

