In the rapidly evolving digital imagery and 3D representation landscape, a new milestone is set by the innovative fusion of 3D Generative Adversarial Networks (GANs) with diffusion models. The significance of this development lies in its ability to address longstanding challenges in the field, particularly the scarcity of 3D training data and the complexities associated with the variable geometry and appearance of digital avatars.
Traditionally, 3D stylization and avatar creation techniques have leaned heavily on transfer learning from pre-trained 3D GAN generators. While these methods brought impressive results, they were plagued by posing bias and demanding computational requirements. Although promising, adversAlthough promising, adversarial finetuning methods faced their issues in text-image correspondence. The non-adversarial finetuning methods offered some respite but were not without their limitations, often struggling to balance diversity with the degree of style transfer.
The introduction of DiffusionGAN3D by researchers from Alibaba Group marks a significant leap in this domain. The framework ingeniously integrates pre-trained 3D generative models with text-to-image diffusion models, establishing a robust foundation for stable and high-quality avatar generation directly from text inputs. This integration is not just about combining two technologies; it’s a harmonious blend that leverages each component’s strengths to overcome the other component’s strengths to overcome other’s limitations and powerful priors, guiding the 3D generator’s finetuning flexibly and efficiently.
A deeper dive into the methodology reveals a relative distance loss. This novel addition is crucial in enhancing diversity during domain adaption, addressing the loss of diversity often seen with the SDS technique. The framework also employs a diffusion-guided reconstruction loss, a strategic move designed to improve texture quality for domain adaption and avatar generation tasks. These methodological enhancements are pivotal in addressing previous shortcomings, offering a more refined and effective approach to 3D generation.
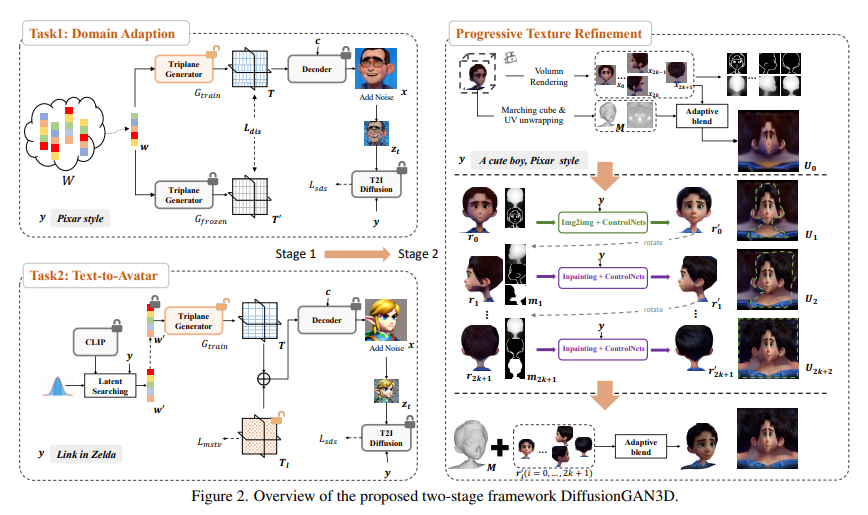
The performance of the DiffusionGAN3D framework is nothing short of impressive. Extensive experiments showcase its superior performance in domain adaption and avatar generation, outshining existing methods regarding generation quality and efficiency. The framework demonstrates remarkable capabilities in generating stable, high-quality avatars and adapting domains with significant detail and fidelity. Its success is a testament to the power of integrating different technological approaches to create something greater than the sum of its parts.
In conclusion, the key takeaways from this development include:
- DiffusionGAN3D sets a new standard in 3D avatar generation and domain adaption.
- Integrating 3D GANs with diffusion models addresses longstanding challenges in the field.
- Innovative features like relative distance loss and diffusion-guided reconstruction loss significantly enhance the framework’s performance.
- The framework outperforms existing methods, significantly advancing digital imagery and 3D representation.
Check out the Paper and Project. All credit for this research goes to the researchers of this project. Also, don’t forget to join our 35k+ ML SubReddit, 41k+ Facebook Community, Discord Channel, LinkedIn Group, and Email Newsletter, where we share the latest AI research news, cool AI projects, and more.
If you like our work, you will love our newsletter..
Hello, My name is Adnan Hassan. I am a consulting intern at Marktechpost and soon to be a management trainee at American Express. I am currently pursuing a dual degree at the Indian Institute of Technology, Kharagpur. I am passionate about technology and want to create new products that make a difference.