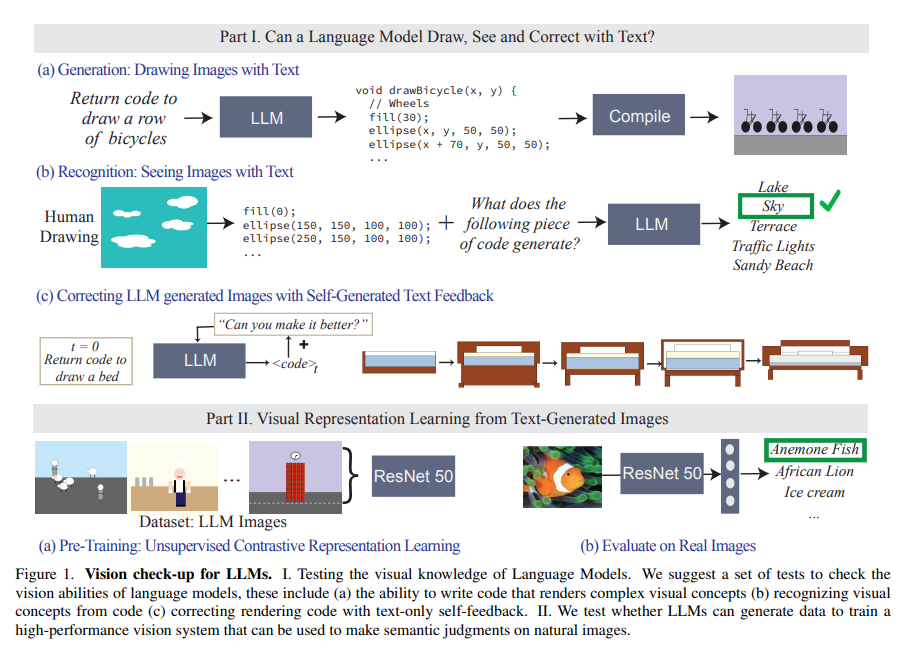
The study investigates how text-based models like LLMs perceive and interpret visual information in exploring the intersection of language models and visual understanding. The research ventures into uncharted territory, probing the extent to which models designed for text processing can encapsulate and depict visual concepts, a challenging area considering the inherent non-visual nature of these models.
The core issue addressed by the research is assessing the capabilities of LLMs, predominantly trained on textual data, in their comprehension and representation of the visual world. Earlier, language models do not process visual data in image form. The study aims to explore the boundaries and competencies of LLMs in generating and recognizing visual concepts, delving into how well text-based models can navigate the domain of visual perception.
Current methods primarily see LLMs like GPT-4 as powerhouses of text generation. However, their proficiency in visual concept generation remains an enigma. Past studies have hinted at LLMs’ potential to grasp perceptual concepts such as shape and color, embedding these aspects in their internal representations. These internal representations align, to some extent, with those learned by dedicated vision models, suggesting a latent potential for visual understanding within text-based models.
The researchers from MIT CSAIL introduced an approach to assess the visual capabilities of LLMs. They adopted a method where LLMs were tasked with generating code to visually render images based on textual descriptions of various visual concepts. This innovative technique effectively circumvents the limitation of LLMs in directly developing pixel-based images, leveraging their textual processing prowess to delve into visual representation.
The methodology was comprehensive and multi-faceted. LLMs were prompted to create executable code from textual descriptions encompassing a range of visual concepts. This generated code was then used to render images depicting these concepts, translating text to visual representation. The researchers rigorously tested the LLMs across a spectrum of complexities, from basic shapes to complex scenes, assessing their image generation and recognition capabilities. The evaluation spanned various visual aspects, including the scenes’ complexity, the concept depiction’s accuracy, and the models’ ability to recognize these visual representations.
The study revealed intriguing results about LLMs’ visual understanding capabilities. These models demonstrated a remarkable aptitude for generating detailed and intricate graphic scenes. However, their performance could have been more uniform across all tasks. While adept at constructing complex scenes, LLMs faced challenges capturing intricate details like texture and precise shapes. An interesting aspect of the study was the use of iterative text-based feedback, which significantly enhanced the models’ capabilities in visual generation. This iterative process pointed towards an adaptive learning capability within LLMs, where they could refine and improve visual representations based on continuous textual input.
The insights gained from the study can be summarized as the following:
- LLMs, primarily designed for text processing, exhibit a significant potential for visual concept understanding.
- The study breaks new ground in demonstrating how text-based models can be adapted to perform tasks traditionally reserved for vision models.
- Text-based iterative feedback emerged as a powerful tool for enhancing LLMs’ visual generation and recognition capabilities.
- The research opens up new possibilities for employing language models in vision-related tasks, suggesting the potential of training vision systems using purely text-based models.
Check out the Paper and Project. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter. Join our 35k+ ML SubReddit, 41k+ Facebook Community, Discord Channel, and LinkedIn Group.
If you like our work, you will love our newsletter..
Hello, My name is Adnan Hassan. I am a consulting intern at Marktechpost and soon to be a management trainee at American Express. I am currently pursuing a dual degree at the Indian Institute of Technology, Kharagpur. I am passionate about technology and want to create new products that make a difference.